Können Urteile von Asylverfahren inhaltlich zusammengefasst werden und gibt es Inhalte die spezifisch mit Länder korrelieren?
Mittels machen-learning können grosse Korpora inhaltlich analysiert werden. Die Analyse von 15’537 deutschsprachigen Urteilen des Bundesverwaltungsgericht in punkto Asyl zeigen, dass sich regionale Konflikte in Form der Topics offenbaren.
„Zu viel des Guten“
Im Englischen wird das Akronym «TMI» dafür verwendet, wenn jemand zu viele Details erzählt, weil es einfach «to much information» ist. Ebenso geht es einem, wenn man sich den Korpus betrachtet, den weblaw.ch für diesen Artikel freundlicherweise zur Verfügung gestellt hat. Nicht weil er zu viele Details beinhaltet, aber weil er schlicht riesig ist: 24’995 Urteile (seit 2006) des Bundesverwaltungsgerichts bezüglich Asylverfahren. Die einzig Möglichkeit, gegen einen negativen Asyl- oder ein Nichteintretens-Entscheid des Staatssekretariats für Migration vorzugehen ist die Beschwerde beim Bundesverwaltungsgericht. Dieses entscheidet als letzte Instanz und dessen Urteile werden im folgenden Analysiert. Das Interesse liegt allerdings nicht auf einer Zusammenstellung relevanter Gesetzesartikel, sondern darauf, ob die Entscheide inhaltlich zusammengefasst werden können.
Das Structural Topic Model
Wenn mit einem derart grossen Korpus gearbeitet wird, ergeben sich durch die Hilfe von Computern neue Möglichkeiten. In diesem Fall, das Errechnen eines „Structural Topic Model“ (STM). Die Idee hinter einem STM ist, dass verschiedene Topics den Inhalt von einem Dokument „erzeugen“. Das Topic ist dabei eine definierte Verteilung über ein Vokabular von Worten. Weiter wird angenommen, dass eine Kollektion von Dokumenten durch verschiedene Topics erzeugt wird. Dabei werden die Dokumente zu unterschiedlicher Wahrscheinlichkeit von den Topics generiert. Als Beispiel kann man sich eine Krimi-Abteilung in der Bibliothek vorstellen: alle Bücher werden sich wohl um Kriminalität, Täter, Opfer und Polizei drehen und entsprechend kommen Wörter assoziiert mit diesem Topic mit einer höheren Wahrscheinlichkeit vor. Aber spielen einige Bücher vielleicht in einer anderen Zeit, an einem anderen Ort oder befassen sich Inhaltlich mit einem spezifischen Thema was wiederum andere Wörter häufiger erscheinen lässt im Buch A im vergleich zum Buch B. Also ist das einzelne Buch eine Mischung aus diesen verschiedenen Topics.
Wie viele Topics geschätzt werden, wird in einem itterativen Prozess bestimmt. Dabei werden Modelle mit unterschiedlicher Anzahl Topics geschätzt und Modellparameter verglichen. In dieser Analyse wird ein Modell mit 6 Topics geschätzt.
Wer sich mit der Methodik auseinandersetzen will, der findet auf dieser Seite Links zu methodischen Papers, Packages und weitere Anwendungsbeispielen. Eine eher mathematische Einführung ist hier zu finden.
Vom Urteil zu Daten
Um Texte als Daten zu verwenden, müssen sie zuerst präpariert werden: Zahlen und Satzzeichen werden entfernt und alles in Kleinbuchstaben umgewandelt. Weiter werden „Stoppworte“ entfernt. Diese sind in der Regel inhaltslos (Pronomen oder „dass“). Im Fall von Urteilen sind dies aber auch Worte die Grundsätzlich vorkommen und in dieser Analyse nicht von Interesse sind: beispielsweise „Art.“ oder „Ziff“.
Nebst dem Text gibt es noch die Metadaten. Diese kennt man beispielsweise als Autorschaft oder Speicherdatum. Im Fall von den Urteilen waren keine vorhanden. Sie sind allerdings für die Analyse von enormer Bedeutung: anhand dieser können die Dokumente in Gruppen aufgeteilt werden. Für die Urteile wurden verschiedene Metadaten generiert. In dieser Analyse wird nur das Herkunftsland der beschwerdestellenden Person für die Gruppierung verwenden. Es musste die Annahme getroffen werden, dass das Herkunftsland der erstgenannten Person (falls mehrer beschwerdeführende Personenen aufgeführt sind) für die Klassifizierung des Dokuments gilt.
Um die Interpretation zu gewährleisten wurden nur in deutsch verfasste Dokumente für die Analyse verwendet. Dies sind allerdings immer noch 15’537 Urteile.
Von den Daten zu den Topics
Nach dem die Vorbereitungen abgeschlossen wurden, konnte das eigentliche STM gerechnet werden. Die folgende Darstellung zeigt die 10 Worte, welche die höchste Wahrscheinlichkeit besitzen von der jeweiligen Topic generiert zu werden.
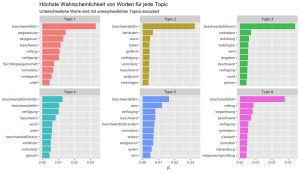
Daten: weblaw.ch ; eigene Berechnungen
Bestimmte Wörter – weil sie zwangsläufig häufig vorkommen – werden bei verschiedenen Topics relativ hoch eingestuft. Nebst dem, dass Wörter mit hoher Auftretenswahrscheinlichkeit analysiert werden, kann dies auch für jene Wörter gemacht werden, welche am «exklusivsten» sind für eine bestimmte Topic:
«FREX» gewichtet Wörter nach Häufigkeit im ganzen Korpus und wie exklusiv sie für ein Topics sind. «LIFT» gewichtet Wörter in dem die Häufigkeit durch die Häufigkeit in anderen Topics geteilt wurde.

Daten: weblaw.ch ; eigene Berechnungen
Korrelation und Interpretation
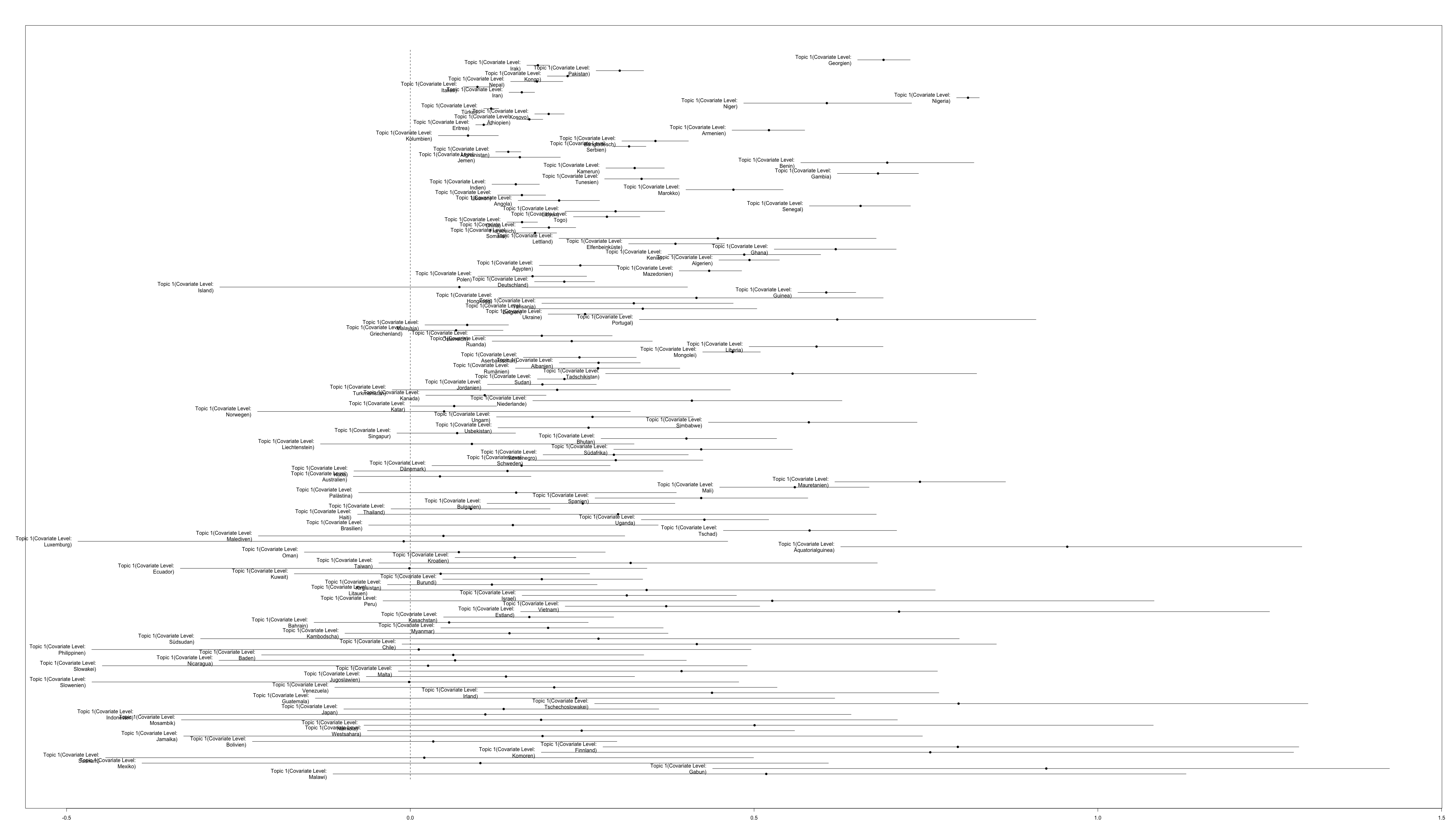
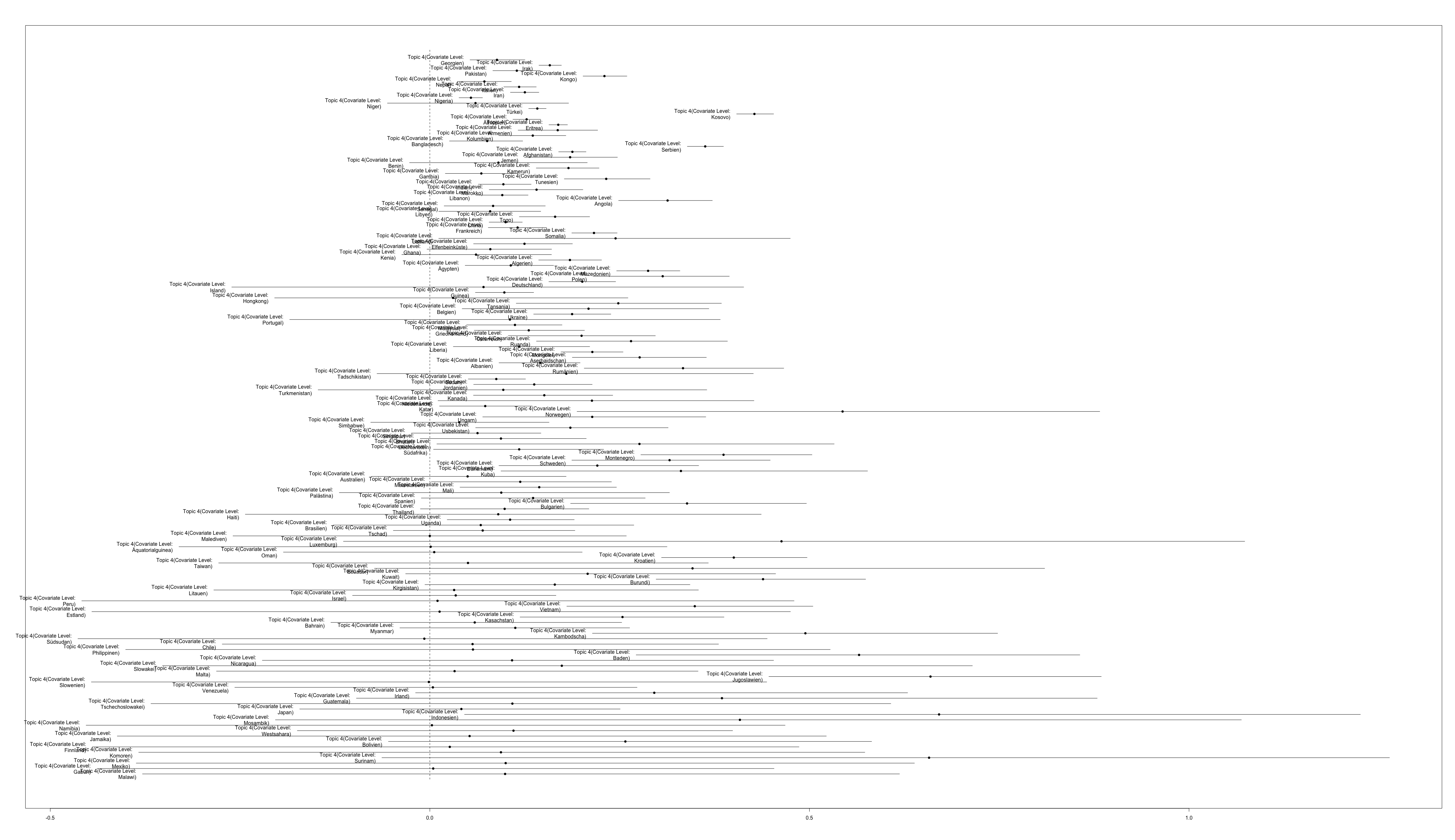
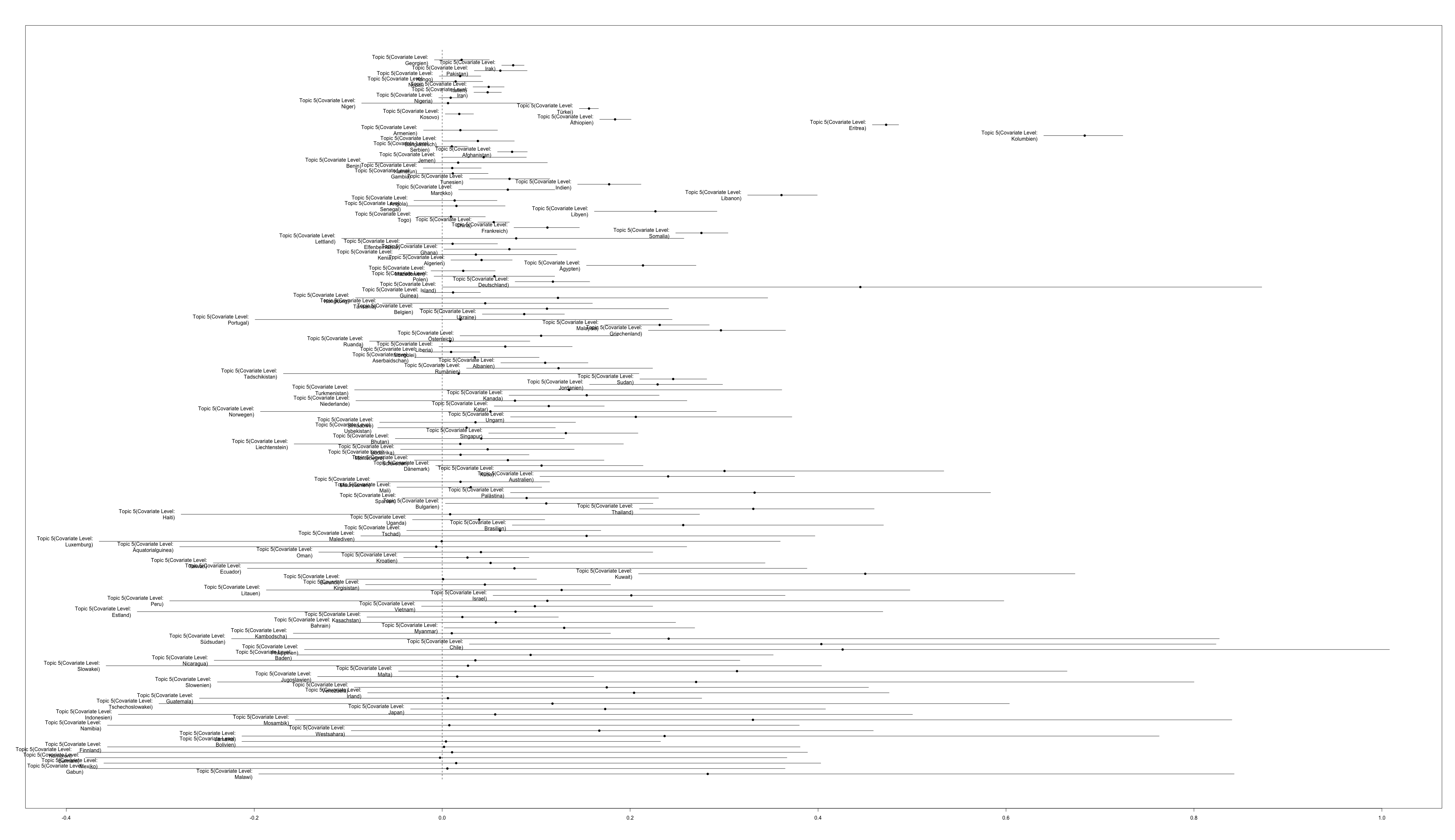
Was nun interessiert, ist, ob bestimmte Topics mit bestimmten Herkunftsländern korrelieren. Da die vom Programm erstellten Grafiken allerdings sehr unübersichtlich sind, können sie hier eingesehen werden: Topic1; Topic2; Topic3; Topic4; Topic5, Topic6.
Eine Liste scheint hier aufschlussreicher. Allerdings werden einfachheitshalber nur die Länder aufgeführt, deren Korrelation (Mittelwert) ca. um die Werte 0.4 und 0.5 liegen:

Daten: weblaw.ch ; eigene Berechnungen
Zu erkennen über die verschiedenen Topics ist, dass verschiedene Organisationen (beispielsweise die linksextremistische DHKP-C aus der Türkei, die türkische Kurden-Partei HADEP später DEHAP- Topic 2; die FARC in Kolumbien, die syrische Partei der Demokratischen Union PYD – Topic 5) in den FREX-Worten auftauchen. Sie weisen auf die Fluchtgründe hin. Einerseits sind diese Organisationen in den Konflikten beteiligt gewesen und können Auslöser für die Flucht von Zivilbevölkerung gewesen sein. Aber kann auch die Mitgliedschaft in einer Organisation den Fluchtgrund darstellen, wenn diese politisch verfolgt und beispielsweise eingesperrt werden. Diese Unterscheidung ist allerdings erst durch das lesen der Dokumente möglich.
Es zeigt sich weiter, dass in den Topics regionale Konflikte zu erkennen sind, so beispielsweise in Topic 6 die militärische Besetzung des Nordens von Sri Lanka. Der Konflikt (1983 bis 2009) war ein Bürgerkrieg zwischen den Liberation Tigers of Tamil Elam und den Regierungstruppen. Ähnlich in Topic 4, mit dem das alte Jugoslawien als Herkunftsland korreliert. Hier werden auch die Ländernamen Bosnien und Kosovo genannt, welche im Zuge der Auflösung Jugoslawiens in den 90er Jahren Kriege erlebten. In Topic 3 entspricht die Besatzung des Tibets durch China einem solchen regionalen Konflikt. Ebenso sind regionale Konflikte das Thema in Topic 2. Einerseits widerspiegelt sich die Situation der Kurden in der Türkei durch das Auftreten der Worte: HADEP oder PKK – die kurdische Arbeiterpartei in der Türkei. Andererseits die Konflikte auf der arabischen Halbinsel – Syrien angezeigt durch die PYD, oder Iran und Jemen durch die hohe Korrelation mit der Topic. Als letztes, wenn auch nicht mehr so deutlich zeigt sich der regionale Bezug in Topic 1 zu afrikanischen Ländern in den positiven Korrelationen.
In Topic 4 sind auch Worte wie Asylwiderwider, Wiedererwägung oder Revision deutlich vertreten. Dies könnte ein Hinweis darauf sein, dass Staaten mit denen dieses Topic korreliert, heute als „Safe-Countries“ angesehen werden und dies sich auch auf den Asylstatus auswirkt.
Wer sich vertieft für die Ergebnisse interessiert, kann sich hier austoben. Man kann die wahrscheinlichsten Worte nach Topics detaillierter inspizieren oder welche Ländernamen von welchem Topic am wahrscheinlichsten generiert werden.
Fazit
Die computerunterstützte Textanalyse ermöglicht, dass grosse Korpora auf einmal verarbeitet werden können, aber die Interpretation der Resultate ist keine einfache Sache. Diese kann nicht dem Computer überlassen werden. Die Topics korrelieren mit den Herkunftsländern, aber die generierten Wortlisten müssen detaillierter Betrachtet werden, als dies hier möglich ist. Es zeigen sich aber bereits dass, die Dokumente inhaltlich zusammenfallen und eine substanzielle Interpretation der Topics möglich ist. Eine interdisziplinäre Analyse der Ergebnisse – beispielsweise mit einem/einer HistorikerInnen oder ExpertInnen in puncto Asylrecht – könnte dies einen vertieften Einblick ergeben. Weiter ist die Bearbeitung der Daten hier noch nicht am Ende. Es gibt noch weitere Metadaten, welche auf ihre Auswertung warten.
Anmerkungen zum Blogbeitrag
Titel: Die Textanalyse von Urteilen – ein erster Versuch
Tobias Ackermann (tobias.ackermann@uzh.ch)
Matrikelnummer: 10-528-784
Politischer Datenjournalismus (Frühlingssemester 2017)
Dozierende: Dr. Bruno Wüest, Alexandra Kohler Abgabedatum: 27.05.2018 Daten: zur Verfügung gestellt von www.weblaw.ch
Anzahl Wörter: 1136 (exkl. Titel und Lead, Grafikbeschriftungen) Feature Image: https://pxhere.com/ro/photo/1154972
R-Script: Script

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}